How is dexFreight utilizing machine learning to improve logistics operations and reduce data silos?
Introduction
At dexFreight, machine learning is the heart and soul of information discovery for ourselves and for our customers. We believe leveraging machine learning early on, serves our interests now and in the future. In many ways, we have been designing dexFreight as a closed-loop complex system that requires persistent feedback from users in order to understand the outside environment that will affect the performance of the marketplace. Otherwise, there is no “learning” in machine learning.
With a team of engineers, we have begun to build the system. For the past six months, we have been designing, brainstorming, talking to customers about how to pack this “intelligence” in the marketplace.
We realized that a lot of companies claim to use machine learning, in fact they don’t. They have hardcoded “if-else-then” logic in their system, but they lack the true power of machine learning which is the “learning” part (feedback mechanism). Using machine learning, we are building (some are being deployed) following decision support tools for the users to interact with the marketplace, collaborate with other logistics companies, and increase their efficiency to process shipments.
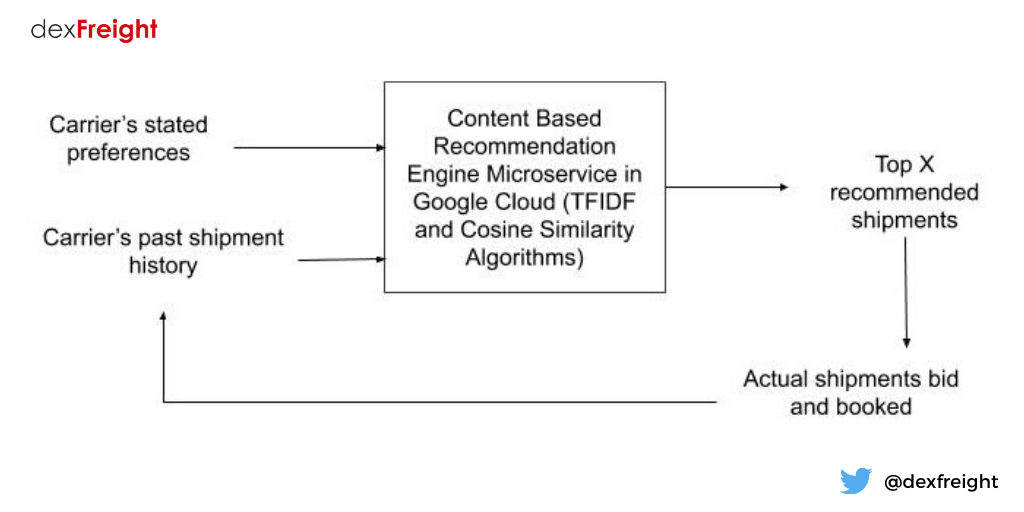
Content-based shipment recommendation engine for carriers
As a marketplace for truckload spot market, we have access to shipments posted by 16,000 freight brokers firms in the US. In order to prevent carriers from being overwhelmed with loads and save them time, we implemented a content-based recommendation engine, which uses TF IDF and Cosine similarity algorithms to search for shipments and present the carriers with a small set of shipments with high probability of being accepted by them.
.png?width=800&name=Data-Science-and-Machine-Learning-at-dexFreight%20(1).png)
As carriers bid on shipments and book them, the information is stored in a large historic state matrix which is then used to “learn” if a carrier will bid on certain types of loads with higher probability. The model then assigns matching percentage and probability that the load will be bid on by carriers and presented to both brokers/shippers and carriers. This reduces the time carriers need to sort through thousands of shipments and also provides brokers with confidence that their shipment will be booked within allocated time window.
We are modeling the recommendation system in Python/MongoDB and have tested the performance in cloud environment, to ensure optimum historical data is used in the model to balance the trade-off between large input data and performance.
Pricing strategy for brokers
Our customers told us that one of the most puzzling (and probably difficult) activities in their daily operation is to price a shipment. At the moment, they have three sources of information to price a shipment — historical price, most recent price, online pricing tools. Even with this information, it turns out they can still end up massively underpricing their shipments. The objective they told us, is to reduce the probability of underpricing their shipments. What they lack is the constant “feedback” or “learning” of how they performed in pricing past shipments, which sets a base for future performance. And that is the niche where they need a better tool. Bigger companies probably have it, but not most small and medium enterprises (SME).
.jpeg?width=800&name=price-strategy-for-brokers%20(1).jpeg)
The first stage, is to provide the users with a broad view of price swings in the market with 20-day moving averages and other indicators. The second stage is to provide a short term forecast of shipment pricing using ARMA model. The third stage is to give the users confidence that their price is competitive compared to the market price. The final stage is to create a feedback matrix of recommended price vs offer price as well as offer price vs. booked price by brokers/shippers. This will allow us to test a variety of supervised learning models to determine the likelihood that the shipment will be booked in a given time window.
Data asset pricing in Web 3 marketplace
We are huge believers of Web 3 movement. We hold a firm belief that users always have the first right to their data and be able to monetize it. This belief has led us to partner with Ocean Protocol/BigchainDB and create a much-needed logistics data marketplace powered by smart contracts, whereby companies can buy and sell logistics data at their will and change the “rent seeking” paradigm that has plagued other marketplaces. One of the critical parameters in the data marketplace is pricing or valuation of user (shipment) data.
The fundamental question that we are trying to answer is, “what is the value of a shipment data?” While there are traditional models such as cost-plus model, we feel that alone is not enough to determine time-based pricing of the data. Cost-plus model may be enough to set an initial price. However, the value of data decreases over time (like other perishables) and reaches certain non-zero minima. The decreasing function follows some kind of exponential decay curve. This is where machine learning comes in handy, to learn how the market prices the data over time, eventually allowing us to calibrate the price and curve function accordingly.
.jpeg?width=576&name=what-is-the-value-of-a-shipment-data%20(1).jpeg)
In closing
We are extremely excited to bring the power of data science and machine learning to our users, especially the SMEs that have limited resources to do on their own. By joining dexFreight, these users constitute a part of the larger network and are able to take advantage of a large pool of data in order to make decisions to move shipments more efficiently.
Released on December 21, 2019 on Medium